Extending My WiFi Network - A Breakthrough
Oct 02 2013
I’ve had WiFi in my house ever since we moved in. First there was the regular WiFi built in to the Verizon FiOS router/modem combo unit, which was OK, but it soon became apparent that this would not be sufficient to cover the whole home. There are 4 levels from the basement up to my office and no way would the signal from the base station on the top floor reach all the way down to the basement, or even the ground floor.
The solution? Extend the WiFi signal using some kind of repeater or similar technology.
Replicating WiFi signals using wireless repeaters (or access points set to extend mode) is like the old game of Chinese Whispers. You start off with a good signal and at the point where it starts to taper off you install a wireless repeater that picks up that signal and re-broadcasts it. That signal in turn is picked up by the next distant repeater and so on and so forth. The problem is that the signal degrades at each point, but more importantly due to the nature of how most of them work the wireless repeaters basically half your bandwidth at each point. You end up with an unreliable network with a fraction of your potential full bandwidth.
This is not a good solution.
The alternative is to extend your wireless network through wired means. This may sound silly -- why would you even use WiFi if you had wired connections available? But think iPads, iPhones, laptops with no Ethernet connector and other mobile technology. You need WiFi.
Utilizing wired connections would usually entail running lengths of Ethernet cable down through the wall spaces. If this is feasible you would then attach additional wireless access points (WAPs) where the cables emerge, the other end connected directly to your router or through a switch. These access points should be configured using the exact same parameters (same technology [A/B/G/N], same SSID, same security settings etc) as the primary one. In theory then you’re good to go.
For most people, me included, running cables through walls and floors is impractical though. I needed another way to “wire” my house.
The solution? Powerline adapters, also known as HomePlug devices.
Now I’d always considered any device that attempted to push network traffic over your home’s electrical circuits to be absolutely last resort and unreliable and slow at best. That may have been the case many years ago but I was very pleasantly surprised to discover that things have come a long way in recent years with this technology. NetGear amongst others sell some really good Powerline equipment. You plug one in to an electrical outlet near your primary router, connecting it to that router with an Ethernet cable. At distant locations in your house you plug other adapters in where you need network access and you essentially then have the ability to plug a network cable in at that point and connect on up to your main router, wired fashion.
So now I had networked my home, extending the wired network using Powerline adapters. All I needed to do to extend WiFi throughout the house was to, as previously mentioned, attach additional wireless access points to the adapters where I most needed them. Set each one up with identical parameters to the main base station and we’re done.
I thought I’d figured it out. I thought I had it all working. I had a nice Apple AirPort Extreme acting as the primary WiFi base station plugged in to my Verizon router/modem combo. The AirPort Extreme was set to work in bridged mode to avoid any double NAT issues. I then had a number of Apple AirPort Express WiFi access points plugged in to the Powerline adapters and carefully configured identically.
I was happy. It all seemed to work OK.
Frequently however, I experienced really poor network connectivity, specifically on the iPads and iPhones when streaming video for example. I’d read horror stories of issues with Verizon FiOS and YouTube, Verizon’s home router/modems and Google’s Content Delivery Networks (CDNs) and put it down to any of those possibly being the problem. But my other non-WiFi hard-wired systems at home didn’t seem to suffer from these issues. Perhaps it was the AirPort Expresses acting up, or maybe the combination of access points and Powerline adapters. Or maybe it was just the Powerline adapters themselves being unreliable after all. Maybe I’d been too hasty in my endorsement of them. But I never really took the time to fully investigate what the cause of the poor performance was.
Eventually I became annoyed at the inability of the iDevices to reliably stream video over WiFi and took another look at the WiFi access points.
All of them were identically configured, the same as the AirPort Extreme primary base station. All of them were set to use “automatic” radio channel selection so that shouldn’t be an issue, right? I mean … “automatic” I would assume to mean something like ”look to see how busy the channel is that I’m trying to use and if it’s too busy use another one”. At least that was my naive interpretation of how I thought it may work.
Out of desperation and recalling mentions of channel interference between WiFi devices and other household appliances I changed all of the WiFi access points to have individual unique manually selected radio channels.
And you know what? BINGO. Super speed, super reliable connectivity!
So may takeaway on all of this is that perhaps in my home, my wireless access points were just far enough apart that maybe they didn’t “see” one another most of the time and so the automatic channel selection chose the same common channel, but when I was somewhere in the house inbetween points my connection was unknowingly trying to fix on to what it thought was a single signal from one device but was instead rapidly bouncing around from one device to another in a desperate attempt to gain the best connection.
Bottom line -- don’t trust automatic channel selection and instead manually select unique individual spaced-apart channels for each wireless access point.
The solution? Extend the WiFi signal using some kind of repeater or similar technology.
Replicating WiFi signals using wireless repeaters (or access points set to extend mode) is like the old game of Chinese Whispers. You start off with a good signal and at the point where it starts to taper off you install a wireless repeater that picks up that signal and re-broadcasts it. That signal in turn is picked up by the next distant repeater and so on and so forth. The problem is that the signal degrades at each point, but more importantly due to the nature of how most of them work the wireless repeaters basically half your bandwidth at each point. You end up with an unreliable network with a fraction of your potential full bandwidth.
This is not a good solution.
The alternative is to extend your wireless network through wired means. This may sound silly -- why would you even use WiFi if you had wired connections available? But think iPads, iPhones, laptops with no Ethernet connector and other mobile technology. You need WiFi.
Utilizing wired connections would usually entail running lengths of Ethernet cable down through the wall spaces. If this is feasible you would then attach additional wireless access points (WAPs) where the cables emerge, the other end connected directly to your router or through a switch. These access points should be configured using the exact same parameters (same technology [A/B/G/N], same SSID, same security settings etc) as the primary one. In theory then you’re good to go.
For most people, me included, running cables through walls and floors is impractical though. I needed another way to “wire” my house.
The solution? Powerline adapters, also known as HomePlug devices.
Now I’d always considered any device that attempted to push network traffic over your home’s electrical circuits to be absolutely last resort and unreliable and slow at best. That may have been the case many years ago but I was very pleasantly surprised to discover that things have come a long way in recent years with this technology. NetGear amongst others sell some really good Powerline equipment. You plug one in to an electrical outlet near your primary router, connecting it to that router with an Ethernet cable. At distant locations in your house you plug other adapters in where you need network access and you essentially then have the ability to plug a network cable in at that point and connect on up to your main router, wired fashion.
So now I had networked my home, extending the wired network using Powerline adapters. All I needed to do to extend WiFi throughout the house was to, as previously mentioned, attach additional wireless access points to the adapters where I most needed them. Set each one up with identical parameters to the main base station and we’re done.
I thought I’d figured it out. I thought I had it all working. I had a nice Apple AirPort Extreme acting as the primary WiFi base station plugged in to my Verizon router/modem combo. The AirPort Extreme was set to work in bridged mode to avoid any double NAT issues. I then had a number of Apple AirPort Express WiFi access points plugged in to the Powerline adapters and carefully configured identically.
I was happy. It all seemed to work OK.
Frequently however, I experienced really poor network connectivity, specifically on the iPads and iPhones when streaming video for example. I’d read horror stories of issues with Verizon FiOS and YouTube, Verizon’s home router/modems and Google’s Content Delivery Networks (CDNs) and put it down to any of those possibly being the problem. But my other non-WiFi hard-wired systems at home didn’t seem to suffer from these issues. Perhaps it was the AirPort Expresses acting up, or maybe the combination of access points and Powerline adapters. Or maybe it was just the Powerline adapters themselves being unreliable after all. Maybe I’d been too hasty in my endorsement of them. But I never really took the time to fully investigate what the cause of the poor performance was.
Eventually I became annoyed at the inability of the iDevices to reliably stream video over WiFi and took another look at the WiFi access points.
All of them were identically configured, the same as the AirPort Extreme primary base station. All of them were set to use “automatic” radio channel selection so that shouldn’t be an issue, right? I mean … “automatic” I would assume to mean something like ”look to see how busy the channel is that I’m trying to use and if it’s too busy use another one”. At least that was my naive interpretation of how I thought it may work.
Out of desperation and recalling mentions of channel interference between WiFi devices and other household appliances I changed all of the WiFi access points to have individual unique manually selected radio channels.
And you know what? BINGO. Super speed, super reliable connectivity!
So may takeaway on all of this is that perhaps in my home, my wireless access points were just far enough apart that maybe they didn’t “see” one another most of the time and so the automatic channel selection chose the same common channel, but when I was somewhere in the house inbetween points my connection was unknowingly trying to fix on to what it thought was a single signal from one device but was instead rapidly bouncing around from one device to another in a desperate attempt to gain the best connection.
Bottom line -- don’t trust automatic channel selection and instead manually select unique individual spaced-apart channels for each wireless access point.
The Password Minder
Apr 30 2013
Several weeks ago I saw a Twitter post from Mikko Hypponen.
It provided a link to a YouTube video of what was effectively a physical paper note book intended to be used to store your critically sensitive logins and passwords for web sites, email settings and so on. Either the video was an elaborate and hilarious fake, or else there really was such a thing as the “Password Minder”. Many people re-tweeted and wrote about it.
I dismissed it as a likely fake. Surely nobody would be so stupid to consider using a simple paper note pad emblazoned with “Password Minder” on the front with plainly written user names and passwords within and consider it secure? I guess anybody who would use such a thing would soon find it redundant though since every entry would comprise the same user name and password of “password” or “1234” :-)
But then, a couple of weeks ago while I was in the local Barnes & Noble book store, I came across this. I had to snap a photo of it since I was so surprised to see it.


Yes, they (or variations of them) do actually exist! And this one was a bargain too at only $5.98!
Incredible!
Ellen DeGeneres subsequently did a great job of ridiculing the “Password Minder” on her show. Check out this video.
https://www.youtube.com/watch?feature=player_embedded&v=Srh_TV_J144
And no, I didn’t buy one.
The Password Minder features a leather cover to ensure your passwords stay a secret: youtube.com/watch?v=dcjViY…#soconvenient Hat tip to @sjodet
— Mikko Hypponen ✘ (@mikko) March 27, 2013
It provided a link to a YouTube video of what was effectively a physical paper note book intended to be used to store your critically sensitive logins and passwords for web sites, email settings and so on. Either the video was an elaborate and hilarious fake, or else there really was such a thing as the “Password Minder”. Many people re-tweeted and wrote about it.
I dismissed it as a likely fake. Surely nobody would be so stupid to consider using a simple paper note pad emblazoned with “Password Minder” on the front with plainly written user names and passwords within and consider it secure? I guess anybody who would use such a thing would soon find it redundant though since every entry would comprise the same user name and password of “password” or “1234” :-)
But then, a couple of weeks ago while I was in the local Barnes & Noble book store, I came across this. I had to snap a photo of it since I was so surprised to see it.
Yes, they (or variations of them) do actually exist! And this one was a bargain too at only $5.98!
Incredible!
Ellen DeGeneres subsequently did a great job of ridiculing the “Password Minder” on her show. Check out this video.
https://www.youtube.com/watch?feature=player_embedded&v=Srh_TV_J144
And no, I didn’t buy one.
Taking the "Network" out of the LAN
Jun 18 2012
Information technology and network security staff often used to talk about computer networks in terms of candy -- crunchy on the outside, soft in the middle. What they meant by this was that you'd have a tough hard outer "shell" at your network perimeter facing the Internet, with firewalls and other equipment restricting and blocking network traffic. However, once you got passed that into the internal network, everything was open and pretty much unrestricted.
The idea was that nobody would be able to reach the inside from the outside. The inside was trusted and safe; soft. This is still the thought in many of today's enterprise networks.
Today, we have targeted phishing attacks, stealthy state actors seeking valuable intellectual property and exploits of web services all reaching the "soft" internal network. Once inside, the attacker can often scour and scan the network looking for juicier targets, jumping from machine to machine, desktop workstation to workstation, extracting and gathering precious information, all unnoticed.
Typical office local area networks are flat spaces where every system has the ability to determine the presence of others. This is by design. It's how Ethernet networking works. At a slightly higher level, each system can often connect to and share information with those other systems to some extent if they are configured to do so, which is often the default.
But why, especially in a modern "secure" business environment, does each workstation for example need to be able to see and communicate with other workstations?
There will always be a need for user's computers to access required servers that may be on the same network segment (DHCP, file servers, domain controllers, Active Directory servers, print servers, DNS etc), but surely there is no need on your typical LAN for all of the bog standard desktop workstations to be able to communicate directly with each other?
Breaking the communications channel between workstations should have no adverse effect. This could/should be done at the switch/router level, preferably at layer 2. Having the control at this level would avoid the need to configure each workstation individually and also avoids the possibility of malware or the users themselves disabling this protection on their own systems.
What would the benefits be?
Imagine the user's workstation gets hit with some nasty worm or stealthy malware for example, possibly coming in through email. All that the user's system would be able to see on the network would be the required servers mentioned previously, which are hopefully locked down. The user's workstation would in effect appear to be the only visible workstation on the network. The malware couldn't spread automatically to anywhere else. There would be no jumping off point. No other systems for the malware to scan and explore. Nothing to see here at all!
Why isn't this the default for secure LANs and why isn't this feature more commonly available and implemented?
I do know that Cisco offers something called Private VLANs that appears to offer this functionality, but I wouldn't say that its use is common or well known.
I think more use of such a feature could significantly raise the bar for secure LANs.
The idea was that nobody would be able to reach the inside from the outside. The inside was trusted and safe; soft. This is still the thought in many of today's enterprise networks.
Today, we have targeted phishing attacks, stealthy state actors seeking valuable intellectual property and exploits of web services all reaching the "soft" internal network. Once inside, the attacker can often scour and scan the network looking for juicier targets, jumping from machine to machine, desktop workstation to workstation, extracting and gathering precious information, all unnoticed.
Typical office local area networks are flat spaces where every system has the ability to determine the presence of others. This is by design. It's how Ethernet networking works. At a slightly higher level, each system can often connect to and share information with those other systems to some extent if they are configured to do so, which is often the default.
But why, especially in a modern "secure" business environment, does each workstation for example need to be able to see and communicate with other workstations?
There will always be a need for user's computers to access required servers that may be on the same network segment (DHCP, file servers, domain controllers, Active Directory servers, print servers, DNS etc), but surely there is no need on your typical LAN for all of the bog standard desktop workstations to be able to communicate directly with each other?
Breaking the communications channel between workstations should have no adverse effect. This could/should be done at the switch/router level, preferably at layer 2. Having the control at this level would avoid the need to configure each workstation individually and also avoids the possibility of malware or the users themselves disabling this protection on their own systems.
What would the benefits be?
Imagine the user's workstation gets hit with some nasty worm or stealthy malware for example, possibly coming in through email. All that the user's system would be able to see on the network would be the required servers mentioned previously, which are hopefully locked down. The user's workstation would in effect appear to be the only visible workstation on the network. The malware couldn't spread automatically to anywhere else. There would be no jumping off point. No other systems for the malware to scan and explore. Nothing to see here at all!
Why isn't this the default for secure LANs and why isn't this feature more commonly available and implemented?
I do know that Cisco offers something called Private VLANs that appears to offer this functionality, but I wouldn't say that its use is common or well known.
I think more use of such a feature could significantly raise the bar for secure LANs.
YouPorn Passwords
Feb 23 2012
Customer details of registered users of the website YouPorn were recently revealed after a third-party chat service "failed to take the appropriate precautions in securing its user data”. According to various reports, it resulted in an estimated 1 million user names, email addresses and plain-text passwords being exposed, much to the embarrassment of those individuals I’m sure. My tests saw closer to 2 million unique usernames extracted from the files so I’m not sure why the discrepancy.
Since the data is now effectively in the public domain, I did a quick analysis of the passwords. While some may be attributed to the nature of the content of the aforementioned site, others are the usual suspects, with “123456” taking top honors by a large margin.
Here are the top 50.
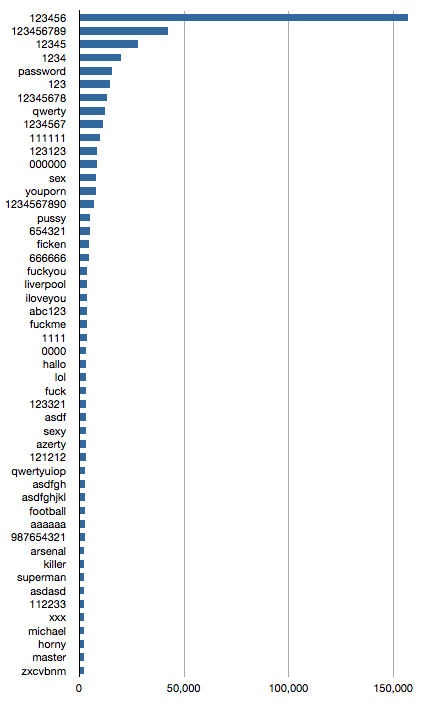
Since the data is now effectively in the public domain, I did a quick analysis of the passwords. While some may be attributed to the nature of the content of the aforementioned site, others are the usual suspects, with “123456” taking top honors by a large margin.
Here are the top 50.
Increased Bandwidth = Slower UDP scans?
Feb 07 2012
I recently finished up a marathon debugging and research session attempting to solve an issue in a network scanning application where, if the code was run on Windows Server 2003, scanning a large number of UDP ports completed significantly quicker than when the exact same software was run on Windows Server 2008 R2. The tests even went so far as to be run on the exact same hardware, re-imaging the box between the 2 configurations. And yet the problem persisted.
I had seen KB articles and patches available for WIN2K8R2 that allegedly fixed some latency issues around UDP processing, but we were at SP1 and this was already in place. Regardless, the code that was responsible for sending and receiving the UDP packets on the network was written to use WinPcap, the low level packet capture driver for Windows, and thus should not have suffered from any (comparatively) higher-level changes made in the TCP/IP stack between operating systems.
All manner of extensive tests were run to try to nail down why the scans took so much longer on 2008 R2.
To cut a very long story short, the issue was with the network card driver.
Now usually when I investigate networking problems like this, the very first thing I do is check the NIC settings to make sure they are all correct. Usually the NIC should be in "auto-configure" or "auto-detect" mode and operating in full-duplex. Indeed I had briefly initially looked at both system's NIC properties and both reported to be running at 1 Gbps full-duplex. Nothing to see here. Move on. About the only difference in this area was that the 2K3 box was using older Intel PROSet drivers. Surely nothing major had changed or been fixed since those were released though, right?
Fast forward a number of agonizing days of further debugging and instead of trying to find out what's wrong in the application code, I attempt to see if the problem can be reproduced and isolated with something that does not involve our code at all. Enter the wonderful tool Iperf.
Using Iperf in UDP mode it quickly became apparent something was wrong. Throughput tests from the 2K3 system were half that of the WIN2K8R2 box when tested against the same remote Iperf server. Not just roughly half, but almost exactly half! That's too much of a coincidence.
So what could account for half the throughput? Well, if the NIC was not really operating in full-duplex mode and instead was running in half-duplex, that would be half the bandwidth.
I switched both NICs into 100 Mbps full-duplex mode (curiously the configuration properties of the WIN2K3 NIC did not offer a manual selection for 1 Gbps full-duplex despite the summary claiming it was already running that way) and re-ran the Iperf tests. Amazingly both systems now produced exactly the same throughput!
A slew of application tests were launched again with the new manual NIC settings and the problem was gone. Both systems finished their large UDP scans in consistently similar times.
The NIC properties were lying. It wasn't running full-duplex on the WIN2K3 system.
Problem solved.
One last mystery though. How can increased bandwidth (on the WIN2K8R2 box running 1 Gbps full-duplex versus WIN2K3 running 1 Gbps half-duplex) result in a large UDP scan that runs slower?
To explain this I have to explain how UDP scanning works against typical modern targets.
Most modern operating systems restrict the rate at which they inform the sender if a UDP port is closed (see RFC 1812 and others). They will, for example, only respond once every second with a "closed" ICMP Destination Port Unreachable message regardless of however many probes we've sent that target. Any ports that we've sent probes to that we don't get an explicit "closed" (or "open" for that matter) response from we have to wait for a timeout period in case the packet is slow to arrive.
So imagine we send 100 UDP probes and it takes us 10 seconds to do that. This would represent the 2K3 system running in half-duplex. During that time we may receive 10 "closed" replies (at a rate of 1 every second), assuming that the vast majority of scanned ports are actually closed, which they are in practice. So for 10 of our sent probes we receive the "closed" response pretty much immediately and can log the associated port’s state and be done with it. For the other 90 ports we have to wait for our timeout period to expire and have to retry again in one of the following passes, because we don't know if the packet was lost or filtered or whatever.
Now imagine the same scenario where sending our 100 probes takes instead 2 seconds. This would represent the 2K8R2 system running in full-duplex (OK, I know this isn’t double the throughput but I’m just trying to make a point). During that time we may only receive 2 "closed" responses, leaving 98 ports to have to wait for a timeout.
Scale this up to 65536 ports against dozens of targets and you can see how this mounts up.
With the fixed NIC settings this is expected and correct behavior. The fact that it was faster with the "broken" driver was just a quirk of that configuration. Had the NIC been working correctly we would not be here today discussing this problem since all scans would have taken the same (longer) time.
I had seen KB articles and patches available for WIN2K8R2 that allegedly fixed some latency issues around UDP processing, but we were at SP1 and this was already in place. Regardless, the code that was responsible for sending and receiving the UDP packets on the network was written to use WinPcap, the low level packet capture driver for Windows, and thus should not have suffered from any (comparatively) higher-level changes made in the TCP/IP stack between operating systems.
All manner of extensive tests were run to try to nail down why the scans took so much longer on 2008 R2.
To cut a very long story short, the issue was with the network card driver.
Now usually when I investigate networking problems like this, the very first thing I do is check the NIC settings to make sure they are all correct. Usually the NIC should be in "auto-configure" or "auto-detect" mode and operating in full-duplex. Indeed I had briefly initially looked at both system's NIC properties and both reported to be running at 1 Gbps full-duplex. Nothing to see here. Move on. About the only difference in this area was that the 2K3 box was using older Intel PROSet drivers. Surely nothing major had changed or been fixed since those were released though, right?
Fast forward a number of agonizing days of further debugging and instead of trying to find out what's wrong in the application code, I attempt to see if the problem can be reproduced and isolated with something that does not involve our code at all. Enter the wonderful tool Iperf.
Using Iperf in UDP mode it quickly became apparent something was wrong. Throughput tests from the 2K3 system were half that of the WIN2K8R2 box when tested against the same remote Iperf server. Not just roughly half, but almost exactly half! That's too much of a coincidence.
So what could account for half the throughput? Well, if the NIC was not really operating in full-duplex mode and instead was running in half-duplex, that would be half the bandwidth.
I switched both NICs into 100 Mbps full-duplex mode (curiously the configuration properties of the WIN2K3 NIC did not offer a manual selection for 1 Gbps full-duplex despite the summary claiming it was already running that way) and re-ran the Iperf tests. Amazingly both systems now produced exactly the same throughput!
A slew of application tests were launched again with the new manual NIC settings and the problem was gone. Both systems finished their large UDP scans in consistently similar times.
The NIC properties were lying. It wasn't running full-duplex on the WIN2K3 system.
Problem solved.
One last mystery though. How can increased bandwidth (on the WIN2K8R2 box running 1 Gbps full-duplex versus WIN2K3 running 1 Gbps half-duplex) result in a large UDP scan that runs slower?
To explain this I have to explain how UDP scanning works against typical modern targets.
Most modern operating systems restrict the rate at which they inform the sender if a UDP port is closed (see RFC 1812 and others). They will, for example, only respond once every second with a "closed" ICMP Destination Port Unreachable message regardless of however many probes we've sent that target. Any ports that we've sent probes to that we don't get an explicit "closed" (or "open" for that matter) response from we have to wait for a timeout period in case the packet is slow to arrive.
So imagine we send 100 UDP probes and it takes us 10 seconds to do that. This would represent the 2K3 system running in half-duplex. During that time we may receive 10 "closed" replies (at a rate of 1 every second), assuming that the vast majority of scanned ports are actually closed, which they are in practice. So for 10 of our sent probes we receive the "closed" response pretty much immediately and can log the associated port’s state and be done with it. For the other 90 ports we have to wait for our timeout period to expire and have to retry again in one of the following passes, because we don't know if the packet was lost or filtered or whatever.
Now imagine the same scenario where sending our 100 probes takes instead 2 seconds. This would represent the 2K8R2 system running in full-duplex (OK, I know this isn’t double the throughput but I’m just trying to make a point). During that time we may only receive 2 "closed" responses, leaving 98 ports to have to wait for a timeout.
Scale this up to 65536 ports against dozens of targets and you can see how this mounts up.
With the fixed NIC settings this is expected and correct behavior. The fact that it was faster with the "broken" driver was just a quirk of that configuration. Had the NIC been working correctly we would not be here today discussing this problem since all scans would have taken the same (longer) time.
Moved to pairNIC
Dec 17 2011
Having been a very happy user of pair.com’s web hosting service for many years, I finally bit the bullet and transferred my DNS domain name registrar from Network Solutions to pairNIC. It was a painless process taking less than a week, the vast majority of that time spent waiting for Network Solutions to relinquish the name.
I’d been planning to do this for years but every time my domain was up for renewal I would inevitably leave it until it was too late to risk moving it or had worried it would be too complicated or error prone.
This time I was determined not to let it pass.
Not only is pairNIC half the price of Network Solutions* and keeps my Whois details private at no extra cost, but I bet I won’t be pressured to renew by being spammed by them every other week starting 6 months prior to my domain expiring.
* Actually I was only charged $10 for the next full year since this was a transferral, so in effect this was less than a third the price of Netsol.
I’d been planning to do this for years but every time my domain was up for renewal I would inevitably leave it until it was too late to risk moving it or had worried it would be too complicated or error prone.
This time I was determined not to let it pass.
Not only is pairNIC half the price of Network Solutions* and keeps my Whois details private at no extra cost, but I bet I won’t be pressured to renew by being spammed by them every other week starting 6 months prior to my domain expiring.
* Actually I was only charged $10 for the next full year since this was a transferral, so in effect this was less than a third the price of Netsol.
Point of Sale Failure
Dec 09 2011
This is the story of somebody who visited their local car shop the other day...
While they were sitting waiting for their car to finish being inspected they pulled out a phone and did a quick sweep of the company’s WiFi network, to which they were connected after having received the relevant password from the front desk.
Two systems jumped out as interesting, both Dells, according to their MAC vendor IDs. They had TCP port 445 open, meaning they were most likely Windows PCs with file sharing enabled.
They then launched the FileBrowser SMB file access app against one of the systems. Sure enough there were a whole bunch of shared directories and files available, no password required. A little further digging revealed exactly what this system was. It was one of the point of sale devices (cash registers) from the front desk, sitting wide open on the same WiFi network that all of their customers had access to.
Not only is this a catastrophically dumb idea, but it flies in the face of numerous payment card industry regulatory practices and requirements.
No wonder things like this happen.
While they were sitting waiting for their car to finish being inspected they pulled out a phone and did a quick sweep of the company’s WiFi network, to which they were connected after having received the relevant password from the front desk.
Two systems jumped out as interesting, both Dells, according to their MAC vendor IDs. They had TCP port 445 open, meaning they were most likely Windows PCs with file sharing enabled.
They then launched the FileBrowser SMB file access app against one of the systems. Sure enough there were a whole bunch of shared directories and files available, no password required. A little further digging revealed exactly what this system was. It was one of the point of sale devices (cash registers) from the front desk, sitting wide open on the same WiFi network that all of their customers had access to.
Not only is this a catastrophically dumb idea, but it flies in the face of numerous payment card industry regulatory practices and requirements.
No wonder things like this happen.
iPhone Battery Drain Fix?
Dec 04 2011
Recently I acquired an iPhone 4S. Luckily, despite hearing the horror stories of poor battery performance by some users, I had never experienced any issues myself. I could go a whole day with only a few percentage drops in battery life. Admittedly though I am not a heavy user of my phone, in so far as making and receiving calls go. I was very happy with it.
Then all of a sudden, about a week ago, I noticed that the battery was losing charge at a significantly faster rate, without any increase in my usage.
I would leave the phone fully charged, 100%, next to my bed before I went to sleep and 9 hours later in the morning it was at 58%. WTF?
This went on for days, so I began some experiments in order to isolate the cause.
Turn off all unnecessary notifications, alarms, usage reports, auto time zone detection etc.
No change.
Turn off Bluetooth.
No change.
Turn off WiFi.
No change.
This was crazy. No Bluetooth and no WiFi and yet the battery was dropping 30% to 40% overnight.
My last resort, something that in hindsight I should have tried earlier; a full power-off i.e. holding both buttons down for a couple of seconds and sliding off the power, waiting a few more minutes and starting it up again.
I charged the phone back to 100%, turned Bluetooth and WiFi back on and left the phone next to the bed again ready for the morning, fully expecting no improvement.
The percentage charge value the next morning? 99%!!
So, while I am still none the wiser as to the root cause of the abnormal battery drain issue, in my case at least, performing a complete power off/on cycle solved the problem.
My thinking, since I had turned off both Bluetooth and WiFi in my tests, was that power drain through radio use was not the cause. My software engineering background leads me to think that perhaps there was some process caught in a tight loop, sucking up the CPU and in turn draining the battery. A full power cycle cleared out the culprit process. It’s certainly a possibility.
Then all of a sudden, about a week ago, I noticed that the battery was losing charge at a significantly faster rate, without any increase in my usage.
I would leave the phone fully charged, 100%, next to my bed before I went to sleep and 9 hours later in the morning it was at 58%. WTF?
This went on for days, so I began some experiments in order to isolate the cause.
Turn off all unnecessary notifications, alarms, usage reports, auto time zone detection etc.
No change.
Turn off Bluetooth.
No change.
Turn off WiFi.
No change.
This was crazy. No Bluetooth and no WiFi and yet the battery was dropping 30% to 40% overnight.
My last resort, something that in hindsight I should have tried earlier; a full power-off i.e. holding both buttons down for a couple of seconds and sliding off the power, waiting a few more minutes and starting it up again.
I charged the phone back to 100%, turned Bluetooth and WiFi back on and left the phone next to the bed again ready for the morning, fully expecting no improvement.
The percentage charge value the next morning? 99%!!
So, while I am still none the wiser as to the root cause of the abnormal battery drain issue, in my case at least, performing a complete power off/on cycle solved the problem.
My thinking, since I had turned off both Bluetooth and WiFi in my tests, was that power drain through radio use was not the cause. My software engineering background leads me to think that perhaps there was some process caught in a tight loop, sucking up the CPU and in turn draining the battery. A full power cycle cleared out the culprit process. It’s certainly a possibility.
Gmail Account Hacked?
Nov 21 2011
So, I logged in to Gmail the other day, the first time I’ve been in using the web UI for quite some time. I normally just check Gmail from my iPad or phone.
A very nice feature of their web UI is the ability to see a record of account logon details showing the IP addresses from where your email account was accessed. If Google has detected use of your account from an IP address that it hasn’t seen before it shows a nice big red warning message at the top of the screen and recommends you immediately change your password. Unfortunately it was precisely this kind of message that was presented to me when I logged in.
This is a snippet of my login details showing the offending entry.

Now, I usually access Gmail from home or the near vicinity, which is in Virginia, U.S, so seeing an entry claiming to geo-locate to Oklahoma was a little disturbing. I confirmed that this IP address was a DSL connection originating in that state. Of course I immediately changed my password from its already secure and complex version to an even longer impossibly complex one and checked all of my email rules to ensure they hadn’t been tampered with.
I have a number of questions and observations though.
It is this last question I wonder about. Was it just an attempt at accessing my account (e.g. trying to guess my password, but failing) or was somebody actually able to fully access my account using a successful login?
I hope it’s the former.
I don’t store any sensitive information in Gmail. It’s mainly used as a back-stop account, a secondary spam filter from my primary (non-Gmail) account so I wouldn’t really have lost any sensitive data. Still, it makes you a little paranoid when things like this happen.
[ * OK, I know I’m not immune but I would hope I stand a better chance than the average user at securing my stuff. ]
A very nice feature of their web UI is the ability to see a record of account logon details showing the IP addresses from where your email account was accessed. If Google has detected use of your account from an IP address that it hasn’t seen before it shows a nice big red warning message at the top of the screen and recommends you immediately change your password. Unfortunately it was precisely this kind of message that was presented to me when I logged in.
This is a snippet of my login details showing the offending entry.
Now, I usually access Gmail from home or the near vicinity, which is in Virginia, U.S, so seeing an entry claiming to geo-locate to Oklahoma was a little disturbing. I confirmed that this IP address was a DSL connection originating in that state. Of course I immediately changed my password from its already secure and complex version to an even longer impossibly complex one and checked all of my email rules to ensure they hadn’t been tampered with.
I have a number of questions and observations though.
- I am a security professional and know how to secure my computers and devices. *
- I don’t use computers or devices other than my own to access Gmail and my systems are to the best of my knowledge secure.
- I always use SSL when connecting to Gmail.
- My password was already very strong, long and complex.
- What does Google mean by “accessed”?
It is this last question I wonder about. Was it just an attempt at accessing my account (e.g. trying to guess my password, but failing) or was somebody actually able to fully access my account using a successful login?
I hope it’s the former.
I don’t store any sensitive information in Gmail. It’s mainly used as a back-stop account, a secondary spam filter from my primary (non-Gmail) account so I wouldn’t really have lost any sensitive data. Still, it makes you a little paranoid when things like this happen.
[ * OK, I know I’m not immune but I would hope I stand a better chance than the average user at securing my stuff. ]
Dead MacBook Pro
Nov 09 2011
My MacBook Pro died the day before yesterday. Well, more specifically, the video died.
All of a sudden the machine locked up and the display started flickering and showing odd colors. I tried rebooting several times but more often than not it didn’t seem to progress much beyond the spinning icon directly after startup.
That was when I realized I could remote-desktop (VNC) into the machine where I could see the login screen/desktop and everything appeared to be working just fine. So that told me it was the video card that was the issue.
I had heard about problems with higher than average failure rates for NVIDIA 8600M GT based older MacBook Pros (mine is an early 2008 model). See here.
Apparently my machine fell within the date range and type of malfunctioning models and supposedly Apple had now extended free repairs to affected systems to 4 years since purchase. Could I be in luck? I made an appointment at the local Apple Store Genius Bar for the next morning.
At the Apple Store they confirmed it was indeed the notorious NVIDIA failure and that it would be a free repair! 3 to 5 days until I would get it back.
This morning I received an email saying my machine was fixed and ready to pickup. A one day turnaround, for free. Now that’s pretty good service!
One slightly odd thing is that it appears that Apple zapped my password. The password in place when I booted it up was now blank. That’s a little sneaky and I wish they could have told me about it rather than me wonder why on earth it didn’t seem to want a password when logging in. I guess they just do it routinely when they encounter a password-protected system (but then I did have a Guest account logon enabled, so why not use that?). Anyway, the password is now reinstated and so far so good.
All of a sudden the machine locked up and the display started flickering and showing odd colors. I tried rebooting several times but more often than not it didn’t seem to progress much beyond the spinning icon directly after startup.
That was when I realized I could remote-desktop (VNC) into the machine where I could see the login screen/desktop and everything appeared to be working just fine. So that told me it was the video card that was the issue.
I had heard about problems with higher than average failure rates for NVIDIA 8600M GT based older MacBook Pros (mine is an early 2008 model). See here.
Apparently my machine fell within the date range and type of malfunctioning models and supposedly Apple had now extended free repairs to affected systems to 4 years since purchase. Could I be in luck? I made an appointment at the local Apple Store Genius Bar for the next morning.
At the Apple Store they confirmed it was indeed the notorious NVIDIA failure and that it would be a free repair! 3 to 5 days until I would get it back.
This morning I received an email saying my machine was fixed and ready to pickup. A one day turnaround, for free. Now that’s pretty good service!
One slightly odd thing is that it appears that Apple zapped my password. The password in place when I booted it up was now blank. That’s a little sneaky and I wish they could have told me about it rather than me wonder why on earth it didn’t seem to want a password when logging in. I guess they just do it routinely when they encounter a password-protected system (but then I did have a Guest account logon enabled, so why not use that?). Anyway, the password is now reinstated and so far so good.